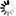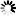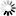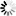Atributový selektor umožňuje vybírat elementy na základě toho, zda obsahují konkrétní atribut, případně atribut s nějakou konkrétní hodnotou.
Nejjednodušší varianta atributového selektoru je pouhé jméno
atributu uvedené v hranatých závorkách,
např. [title]. Takový selektor vybere všechny elementy,
které u sebe mají uveden atribut title
bez ohledu na jeho hodnotu.
Další možností je vybrat elementy, u kterých daný atribut
obsahuj konkrétní hodnotu. V tom případě se do hranatých závorek musí
ještě doplnit porovnání s touto konkrétní hodnotou. Například odstavce
zarovnané doprava pomocí atributu align
můžeme vybrat pomocí p[align="right"].
Před znak = můžeme doplnit ještě další znaky a tím
upravit způsob porovnávání hodnot. Vlnka (~=) způsobí, že
se předpokládá, že atribut obsahuje mezerami oddělený seznam hodnot a
my testujeme, zda se v tomto seznamu nachází konkrétní hodnota.
Pokud bychom například v dokumentu používali atribut data-output pro určení výstupního zařízení, na
kterém se má daný element zobrazovat, například:
<p data-output="mobile tablet pc">Důležitý text</p> <p data-output="pc">Nedůležitá poznámka</p>
Výběr všech elementů, které jsou určené pro osobní počítač,
bychom pak mohli jednoduše realizovat selektorem
*[data-output~="pc"].
Další možností je pro porovnávání použít |=. V
tomto případě se očekává, že hodnota atributu se skládá ze slov
oddělených pomlčkou a testuje se shoda začátku této hodnoty. Asi si
říkáte, k čemu je to dobré. Jednou z mála možností využití je
testování kódů jazyků. V atributu lang
můžeme určit kód jazyka. Jazykový kód americké angličtiny je
en-us, pro britskou to pak je en-gb (více
informací o jazykových kódech a určení jazyka stránky naleznete
v ???). Pokud bychom chtěli vybrat všechny části
dokumentu, které jsou v angličtině, bez ohledu na její variantu,
můžeme použít selektor [lang|="en"].