Těžko říci, zda je typografie umění nebo řemeslo. Není to však důležité. Podstatné je, že za několik set let svého vývoje posbírala množství zkušeností, jak udělat pěknou knihu nebo nějakou jinou tiskovinu. Není to nic jednoduchého – musí se zvolit správný formát papíru, dostatečně velké okraje, vhodný řez a velikost písma. A navíc se musí dodržet mnoho malých detailů při skládání jednotlivých písmen do slov a řádek a řádek pak do celých stránek. S některými pravidly například pro výběr písma jsme se již seznámili v předchozích odstavcích.
Otázkou zůstává, co dalšího z typografie můžeme na prostředí webu aplikovat. Pravdou totiž je, že web je podstatně odlišné médium než papír. Mnoho klasických typografických pravidel proto použít nejde vůbec, některé platí dokonce i obráceně.[11] Pořád však existuje mnoho jednoduchých pravidel, pro mnoho lidí samozřejmých, bez nichž text vypadá nějak divně – ať už je zobrazen na obrazovce počítače, nebo jen vytištěn. Ve většině případů se nejedná o nic speciální, ale o běžné věci z Pravidel českého pravopisu. Když se ale podívám na stránky, které vidím na Internetu, myslím, že není od věci ty nejdůležitější věci zopakovat a říci si, jak se s nimi vypořádat na úrovni HTML.
Začneme interpunkcí. Platí velmi jednoduché pravidlo – mezera se píše jen za interpunkčním znaménky (jako je tečká, čárka, vykřičník a otazník), nikdy ne před nimi. Důvod je velmi prostý. Kdybychom psali mezeru před, mohlo by se interpunkční znaménko přelít na začátek řádky, což rozhodně nevypadá esteticky.[12]
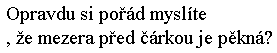
Dalším problematickým znakem jsou uvozovky. Počítačové
klávesnice z psacího stroje převzaly znak `"' jako
náhradu pro uvozovky. Čeština však používá pro každý znak uvozovek
odlišný znak. Správné české uvozovky vypadají „takto“,
angličtina používá odlišný “tvar”. Problém je
však v tom, jak tyto znaky zapsat do HTML kódu, protože běžná
klávesnice je neobsahuje.
Pokud dokument píšeme v kódování, které tyto znaky pokrývá (například utf-8 nebo windows-1250), můžeme je zapisovat přímo:
„text v uvozovkách“
Kromě toho, že se tyto znaky těžko přímo zapisují a musí se často vkládat pomocí nějakého pomocného programu jako je Mapa znaků, není tento přístup vhodný i z toho důvodu, že některé moduly pro změnu kódování češtiny neumí tento znak korektně převést do jiných kódování.
Spolehlivější variantou je zapsání těchto znaků pomocí znakových entit. Jejich název je poněkud krkolomný, ale výsledek určitě stojí za to.
„text v uvozovkách“
HTML nabízí jednu elegantní možnost vkládání uvozovek. Máme k
dispozici element q, který je možné použít pro
označování citací. Prohlížeč by měl obsah elementu uzavřít do
uvozovek. Navíc pokud se několik elementů q vloží
do sebe, bude se znak pro uvozovky měnit. Jediný problém je v tom, že
Internet Explorer uvozovky okolo elementu nedoplní ani ve verzi
6. Jiné prohlížeče jako Opera nebo Mozilla s tím nemají
problém, a stačí v nich proto použít jednoduchý zápis
<q>text v uvozovkách</q>
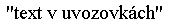
Vidíme, že se místo správných „typografických“ uvozovek použily jen obyčejné. Tento problém lze vyřešit pomocí kaskádových stylů, které umožňují předefinovat znaky používané pro uvozovky. Slouží k tomu vlastnost quotes, která obsahuje seznam znaků používaných pro levé a pravé uvozovky. Pokud uvedeme více párů znaků, použijí se postupně pro jednotlivé úrovně vnoření uvozovek. Protože určení kódování souboru s kaskádovým stylem není úplně snadné, je nejlepší znaky uvozovek zapisovat pomocí jejich unicodového kódu.
q { quotes: "\201E" "\201C" "\201A" "\2018"; }
Pro jistotu můžeme ještě ve stylu definovat, že uvozovky se mají
objevit na začátku a na konci elementu q.
q:before { content: start-quote }
q:after { content: close-quote }
Tímto postupem lze automaticky ošetřit i vnořené uvozovky. Ukážeme si to na jednoduchém příkladě:
<p><q>text v uvozovkách, ve kterém jsou <q>vnořeny další</q>, aby bylo vidět, jak to dopadne</q></p>
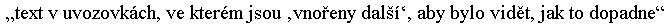
Dalším problematickým znakem je pomlčka. Málokdo dnes ví, jaký je rozdíl mezi znaky `-', `–' a `–'. Většina lidí používá první z nich jako spojovník (k rozdělování slov) i jako pomlčku (při zápisu intervalů a oddělování vět). Je to způsobeno tím, že jedině tento znak je přímo dostupný na klávesnici. Správně bychom však měli spojovník používat jen k rozdělování slov (což v HTML nepřipadá v úvahu, to se buď vůbec nepoužívá, nebo se o něj stará prohlížeč) nebo k oddělování slovních spojení jako „budeme-li“, „společensko-ekonomický“.
Pomlčka existuje ve dvou variantách. Krátká pomlčka `–' se
používá zejména pro zápis intervalů. Např. šířka obrazovky je typicky
800–1280 pixelů. Tento znak můžeme zapsat pohodlně pomocí
znakové entity –:
800–600
Dlouhá pomlčka `–' se používá pro naznačení přestávky v řeči nebo pro výrazné oddělení částí projevu. Např.:
Lidé celého světa – žádný národ nevyjímajíc – touží po míru.
Pro zápis dlouhé pomlčky máme k dispozici rovněž entitu –
—:
Lidé celého světa – žádný národ nevyjímajíc – touží po míru.
Text se „správnými pomlčkami“ vypadá mnohem lépe. Nicméne protože se pomlčky v poslední době nepoužívají zcela správně[13] může zejména dlouhá pomlčka působit na některé čtenáře až nepřirozeně dlouze. Můžeme to obejít použitím krátké pomlčky.
[11] Například na papíře jsou obecně čitelnější patková písma, která vedou oko čtenáře po lince. Na monitorech, které mají oproti tisku směšně malé rozlišení, jsou oproti tomu většinou vhodnější bezpatková písma.
[12] Klasická tištěná typografie doporučuje před některá znaménka vkládat velmi úzkou mezeru. Na obrazovce počítače tyto detaily nerozeznáme, a proto není třeba se s nimi nijak zabývat.
[13] Je to další případ toho, jak počítače ničí kulturu. S nástupem počítačů může dokumenty, časopisy a knihy připravovat v podstatě kdokoliv bez základního typografického vzdělání. Výsledky tomu bohužel často odpovídají.